The Loan Approval Prediction System is an end-to-end machine learning classification project designed to automate, accelerate, and enhance the accuracy of loan approval decisions for financial institutions. In modern digital lending, processing thousands of applications manually introduces significant delays, operational expenses, and potential human bias. This intelligent system mitigates these issues by predicting whether a loan application should be Approved or Rejected based on comprehensive applicant profiles.
By analyzing applicant demographics, financial indicators, and asset valuations, the system helps lenders minimize default risks while maintaining high throughput. Crucially, the model is optimized for real-world business objectives by prioritizing high recall for the 'Approved' class, ensuring that deserving applicants are not mistakenly rejected, thus avoiding lost interest revenue while managing credit default exposure.
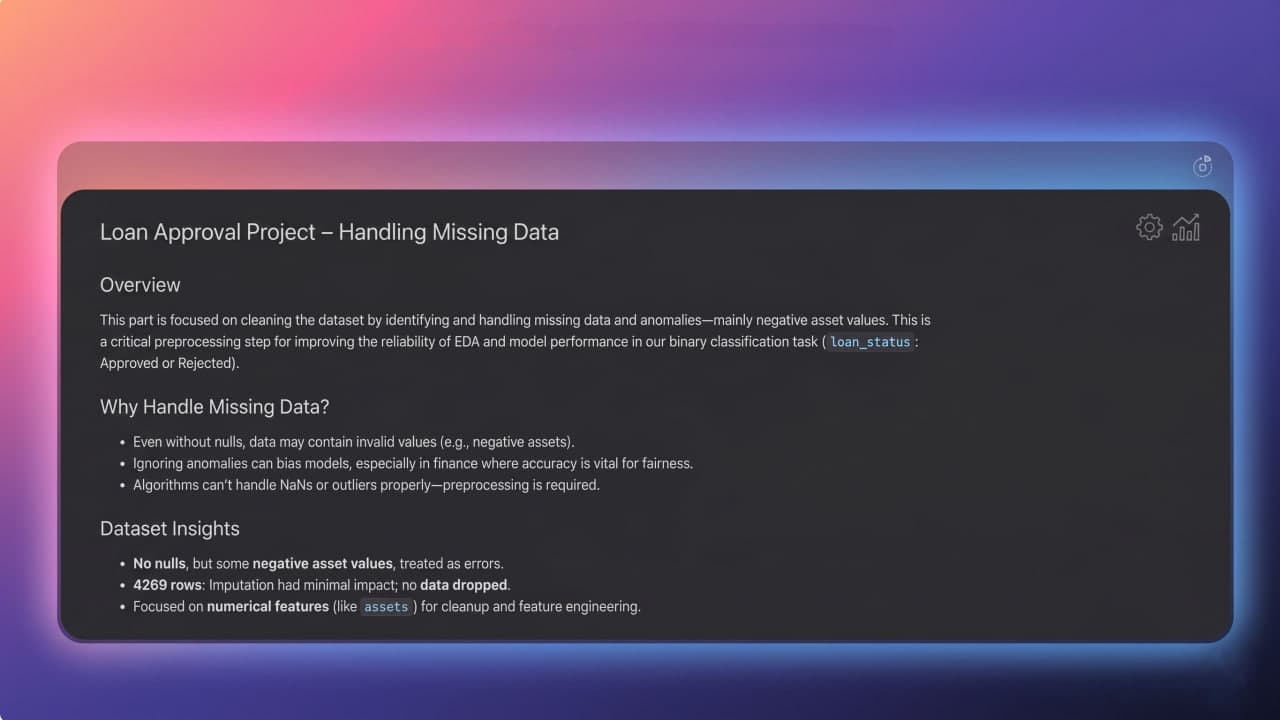
The system is built on a robust data preprocessing and feature engineering pipeline. Starting with a dataset of 4,269 records, it cleans noisy input data (handling negative values and missing fields), applies Label Encoding for categorical features, and derives engineered features such as total asset valuations and debt-to-income ratios to capture affordability. Numerical scaling is applied using StandardScaler before modeling.
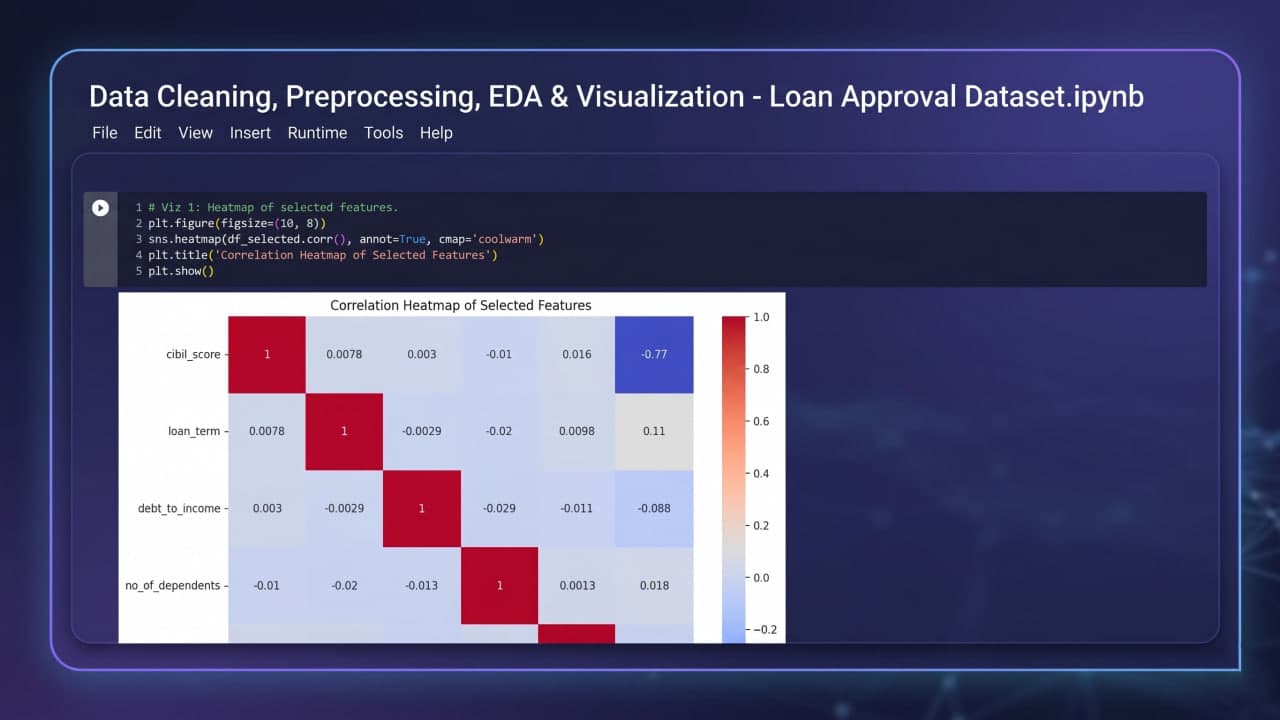
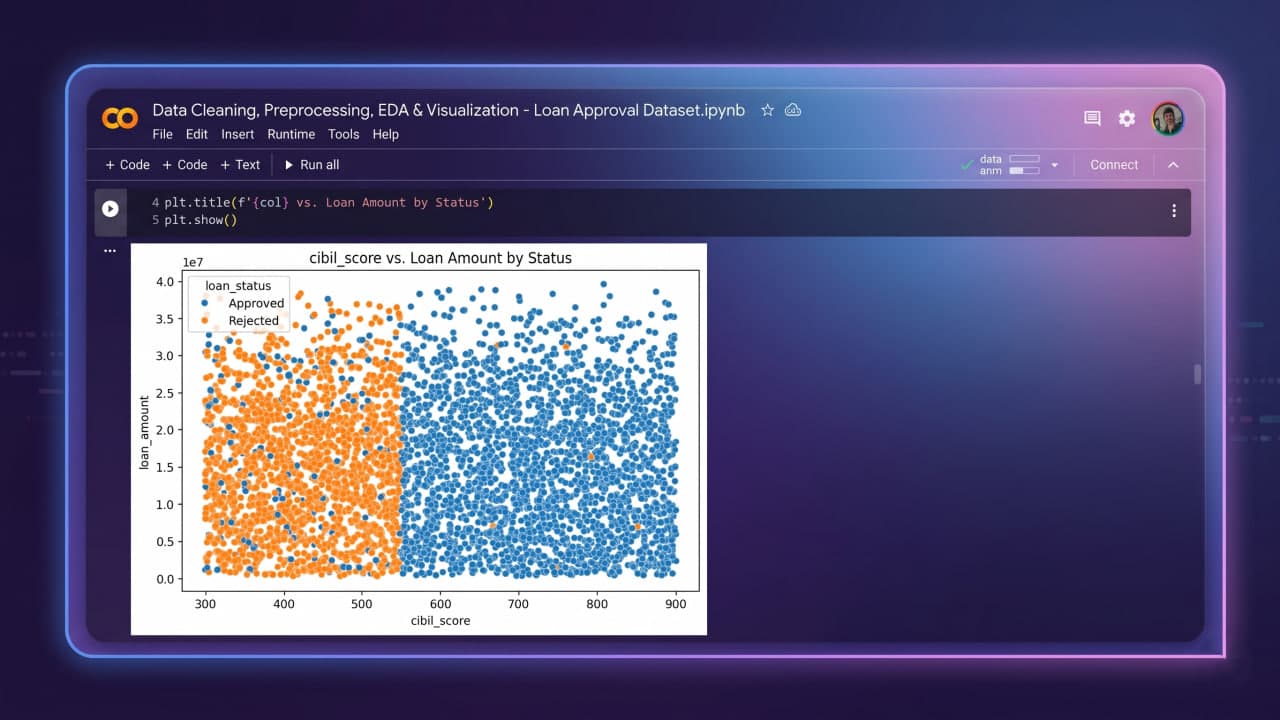
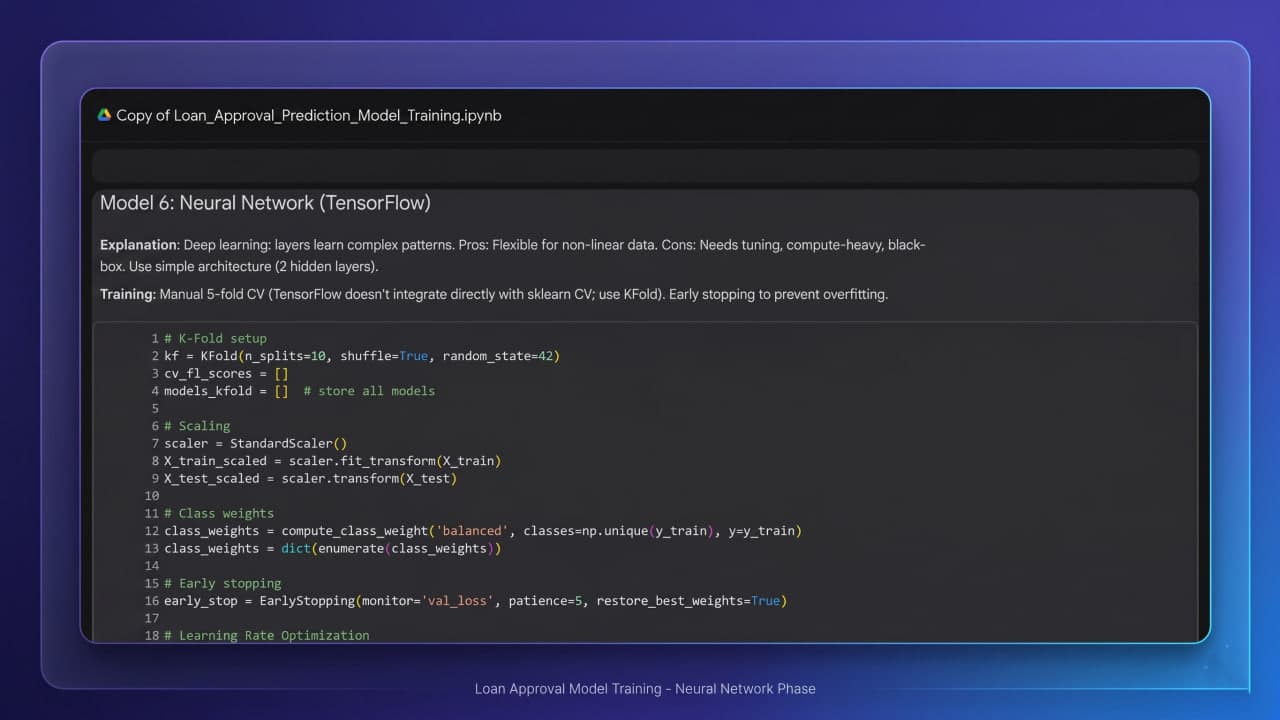
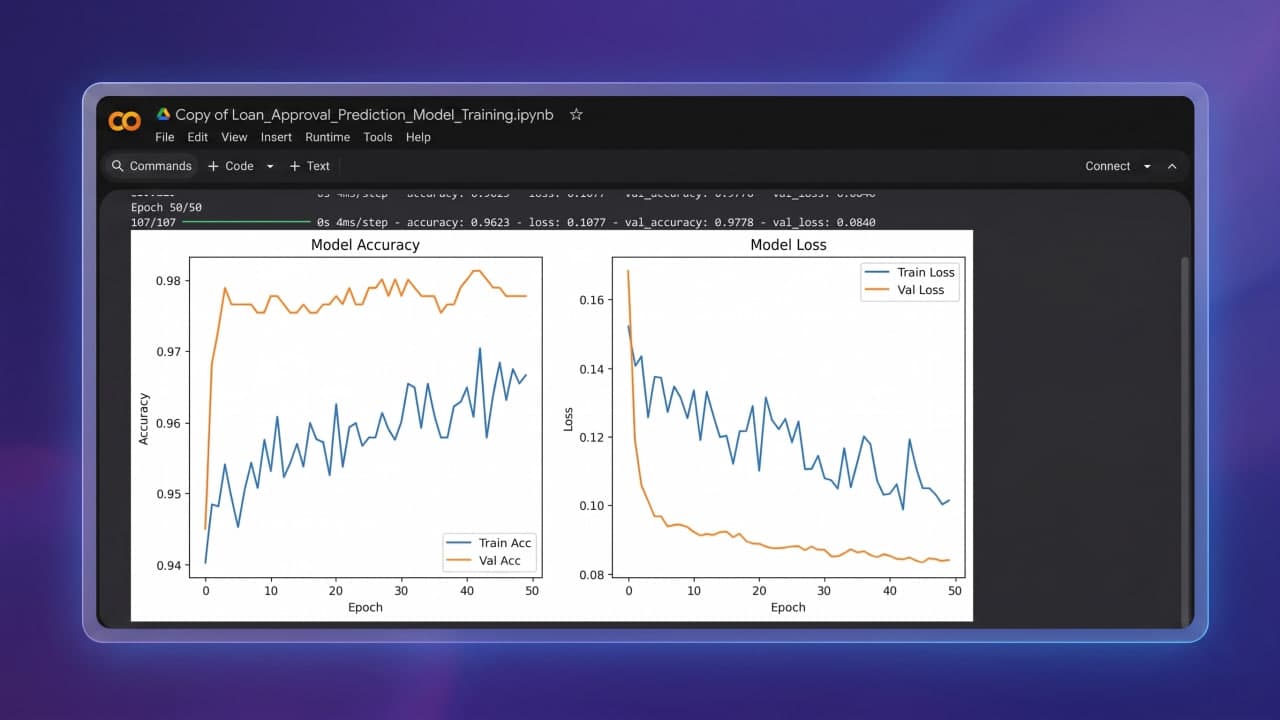
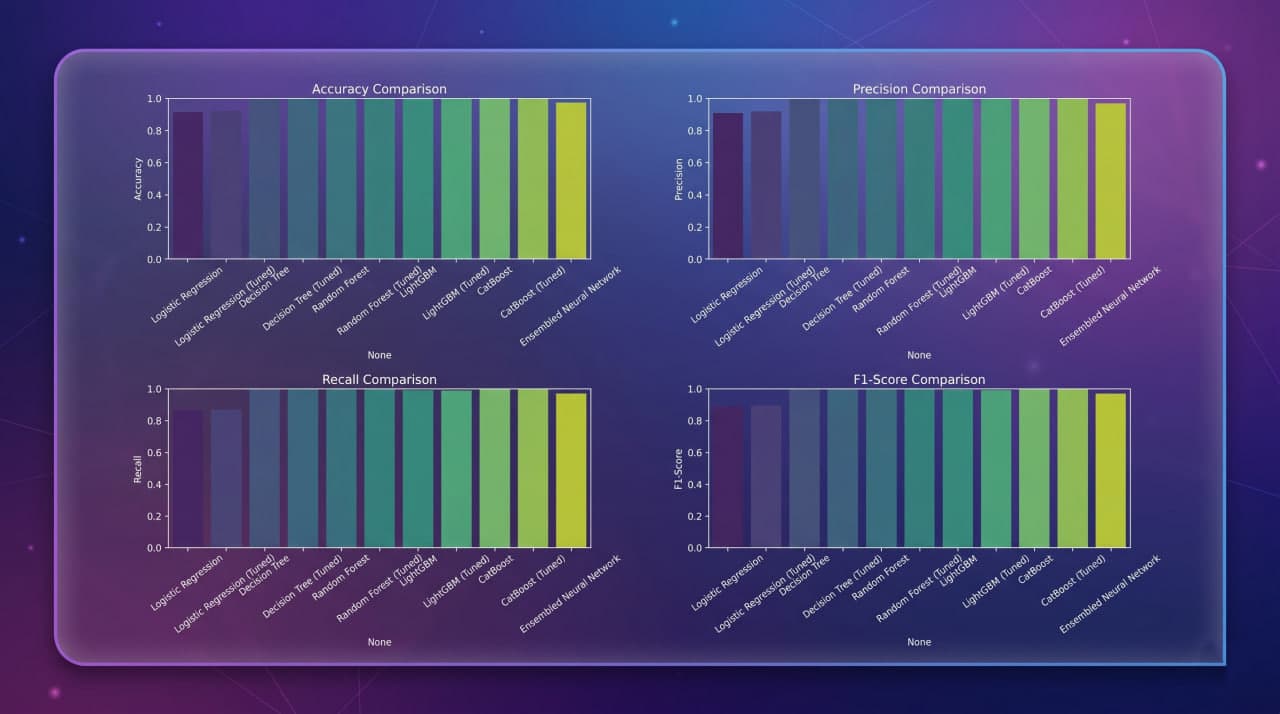
During model development, six distinct classifiers were trained and rigorously evaluated using an 80/20 stratified split and K-Fold Cross Validation. These range from traditional baseline models (Logistic Regression, Decision Trees) and ensemble architectures (Random Forest) to advanced gradient boosting libraries (LightGBM, CatBoost) and deep learning sequential neural networks. Gradient boosting models—particularly CatBoost and LightGBM—demonstrated superior performance, balancing precision and recall effectively. Key insights revealed CIBIL credit scores as the most influential feature in the decision-making process.
To ensure ethical and responsible AI deployment, the project incorporates a fairness audit, analyzing predictions for potential biases related to education levels and employment status. The finalized pipeline is designed for scalability and transparency, ensuring predictions can be interpreted by non-technical banking stakeholders and audited for compliance.
The Challenge
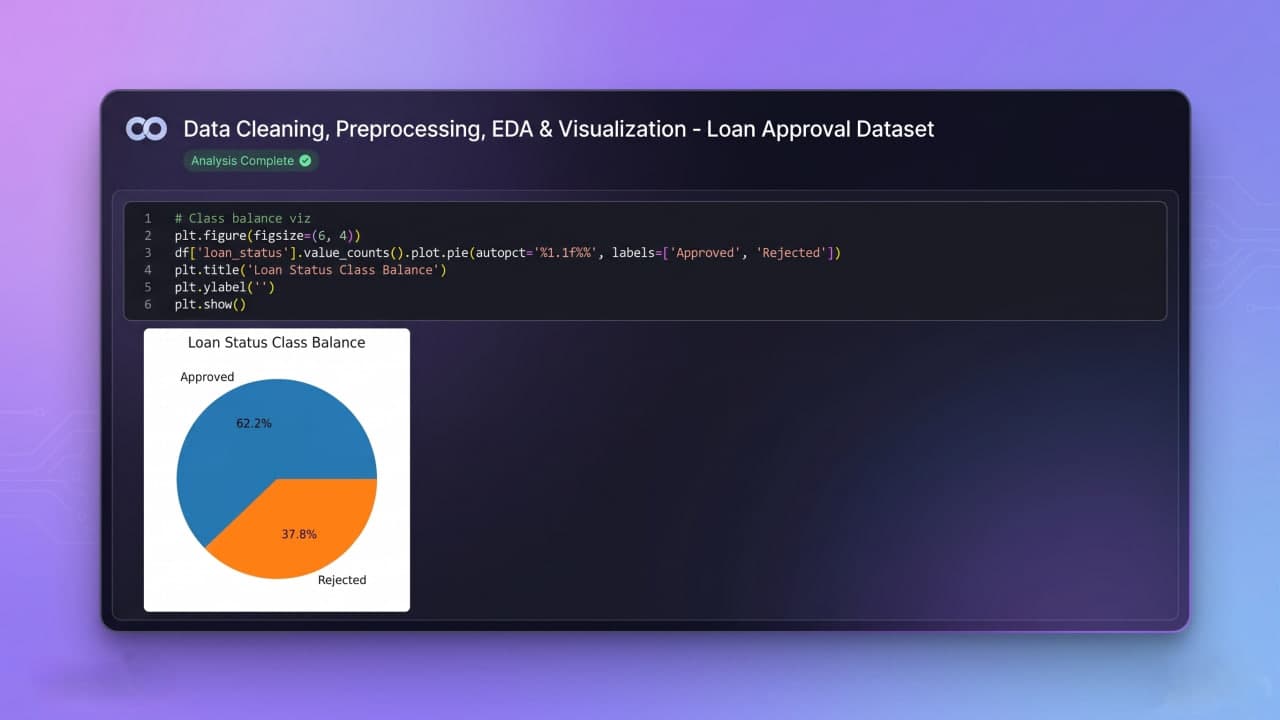
Traditional loan assessment is slow, expensive, and inconsistent. It requires manual review processes that are prone to human error and unconscious bias, while struggling to handle noisy application data, class imbalances, and identifying non-obvious risk indicators.
The Solution
An end-to-end machine learning pipeline that cleans messy data, engineers domain-specific features (such as debt-to-income ratio), and evaluates six different models (including CatBoost, LightGBM, and Deep Learning) to predict loan status with high accuracy and business-aligned recall metrics.
Key Capabilities
Robust data cleaning and preprocessing pipeline handling noisy values and missing entries.
Feature engineering including total asset aggregation and debt-to-income ratio calculations.
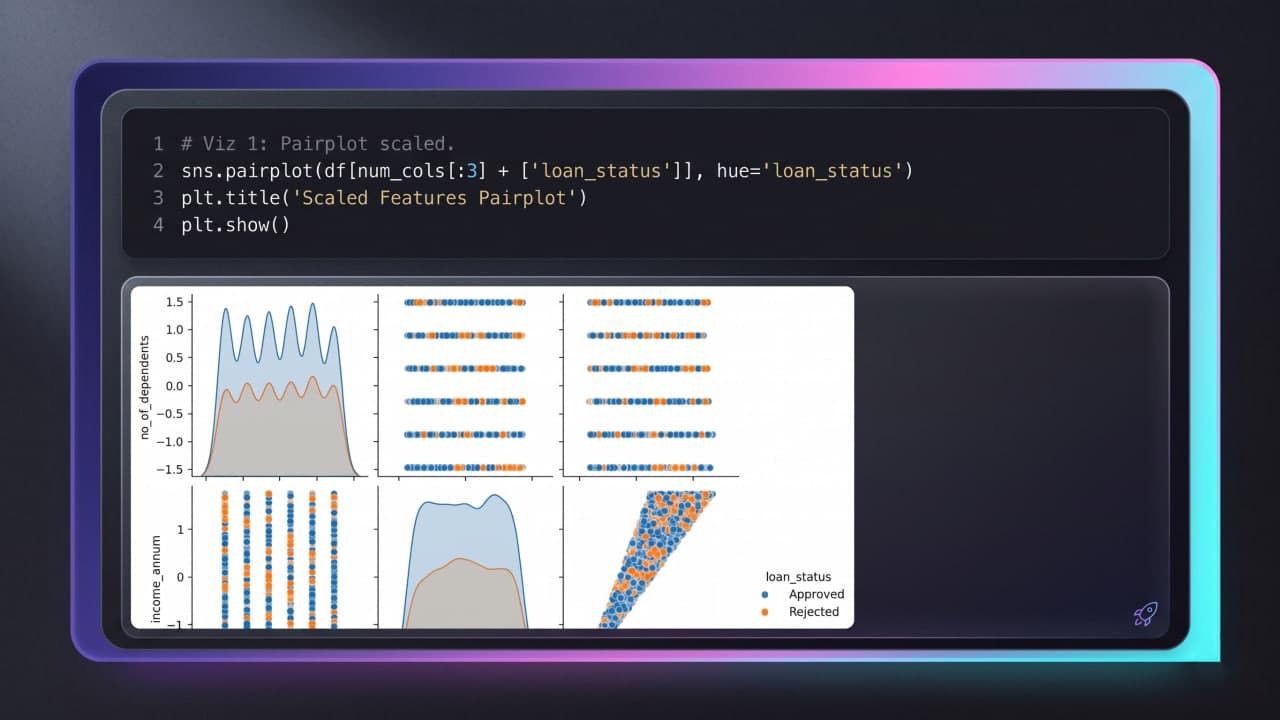
Exploratory Data Analysis (EDA) and visualizations analyzing correlations (e.g., CIBIL score) and distribution patterns.
Comprehensive model evaluation comparing 6 models: Logistic Regression, Decision Tree, Random Forest, LightGBM, CatBoost, and a Sequential Neural Network.
Stratified train-test splitting and K-Fold Cross Validation to ensure generalizability and prevent overfitting.
Ethical fairness auditing analyzing predictions for demographic parity and potential biases.
Visuals


Project Meta
Category
Machine Learning
Tech Stack
PythonPandasNumPyscikit-learnLightGBMCatBoostTensorFlowKerasSeabornJupyter NotebookRepository
Source Code
Continue Exploring
All Projects